 |
Evangelos P. Markatos
Institute of Computer Science (ICS)
Foundation for Research & Technology - Hellas (FORTH)
P.O.Box 1385,
Heraklio, Crete, GR-711-10 GREECE
http://archvlsi.ics.forth.gr markatos@csi.forth.gr
appears in the 2nd IEEE/ACM Int. Symp. on Cluster Computing and the Grid 2002
Although peer-to-peer systems enjoy significant and continually increasing popularity, we still do not have a clear understanding of the magnitude, the traffic patterns, and the potential performance bottlenecks of the recent peer-to-peer networks.
In this paper we study the traffic patterns of Gnutella, a popular large-scale peer-to-peer system, and show that traffic patterns are very bursty even over several time scales. We especially focus on the types of the queries submitted by Gnutella peers, and their associated replies. We show that the queries submitted exhibit significant amounts of locality, that is, queries tend to be frequently and repeatedly submitted. To capitalize on this locality, we propose simple Gnutella caching mechanisms that cache query responses. Using trace-driven simulation we evaluate the effectiveness of Gnutella caching and show that it improves performance by as much as a factor of two.
The first and most widely-known peer-to-peer system, Napster, 1 is a file sharing utility that has enabled hundreds of thousands of users to efficiently share files, including mp3-encoded songs, over the Internet. Capitalizing on the success of Napster, several other peer-to-peer file sharing systems have been recently developed. These include Gnutella, KaZaA, AudioGalaxy, etc. Although the technical details of these systems vary significantly, they all share the peer-to-peer philosophy by enabling all peers to store and deliver content to other peers. Besides file sharing, peer-to-peer systems have also been used for the efficient execution of highly parallel and distributed applications by capitalizing on the availability of idle cycles in home computers. Such applications range from systems that search for extra-terrestrial intelligence [7], to systems that seek a cure for AIDS [5].
Although peer-to-peer systems appeared only recently, their popularity has increased rapidly in the last couple of years. For example, network traffic measurements at the University of Wisconsin suggest that in the period of April 2000, Napster-related traffic represented the 23% of their total network traffic, while at the same time web-related traffic accounted for only 20% [12,13]. Although Napster traffic has been reduced recently, the percentage of peer-to-peer traffic (in total) has actually increased. For example, recent measurement from the University of Wisconsin suggest that, in October 2001, peer-to-peer traffic reached more than 30% of the total traffic2, while at the same time, web-related traffic was a little more than 19%.
Although these measurements suggest that the traffic demands of peer-to-peer systems represent a significant and continually increasing percentage of the overall network traffic, we still do not have a clear understanding of the magnitude, the traffic patterns, and the potential performance bottlenecks of such peer-to-peer networks.
In this paper we study the traffic patterns of Gnutella, a popular large-scale peer-to-peer system. We especially focus on the types of the queries submitted by Gnutella peers, and their associated replies. We identify the locality patterns that exist in Gnutella queries and propose simple, but effective caching mechanisms to exploit them.
More accurately, the contributions of this paper are:
The rest of the paper is organized as follows: Section 2 presents the methodology used to gather Gnutella traces. Section 3 compares our approach with previous work and places our paper in the appropriate context. Section 4 presents the traffic characteristics of the Gnutella network. Section 5 presents and evaluates our caching approach. Finally section 6 concludes the paper.
|
We installed three gnut tracing probes: one in Greece (Crete), one in Norway (Bergen), and one in USA (Rochester, NY). We started the three tracing tools simultaneously on Thursday Oct. 4, 10 am EST. The tracing lasted for about one hour. Each probe recorded the queries and replies received. From the received queries, each probe removed the duplicates, that is, the queries with the same guid that have already been seen and forwarded in the past.
The study of large-scale peer-to-peer systems in general, and Gnutella in particular, is a rather new topic.
Adar and Huberman studied the Gnutella traffic for a 24-hour period [1]. They found that close to 70% of the users shared no files, and that 50% of all responses were returned by only 1% of the hosts. Their findings were independently confirmed by Saroiu et al. who found that ``there is significant heterogeneity and lack of cooperation across peers'' participating in Gnutella [15]. Saroiu et al. findings suggests that a small percentage of the peers appeared to have ``server-like'' characteristics: they were well-connected in the network and they served a significant number of files. This disparity between the peers' characteristics may significantly limit the scalability, reliability and performance of the Gnutella network, and of peer-to-peer systems in general.
Anderson [2] observed the traffic of Gnutella for a 35-hour period and reported several results, including the distribution of TTL values, the distribution of Hops for Queries, the distribution of Hops for all Packets, etc.
Ripeanu et al., studied the topology of the Gnutella network [14] over a period of several months, and found several interesting properties. Among them is that the Gnutella network topology does not match well the underlying Internet topology leading to the inefficient use of the network bandwidth.
Jovanovic [6] studied several Gnutella connection graphs and identified significant performance problems, including short-circuiting, an effect that limits the reachability of the nodes in a Gnutella network. Jovanovic's experiments suggest that, due to short-circuiting, a typical Gnutella peer reaches only about 50% of the peers that it could typically reach.
Sripanidkulchai [16] studied Gnutella traffic and, much like this paper, proposed the use of caching to improve performance. There exist however, several differences between our work and that of Sripanidkulchai. First, we collect Gnutella traces simultaneously from three different points on the Globe in order to make sure that our approach is not specific to one geographic region. Second, our definition of caching is fundamentally different from that in Sripanidkulchai . For example, Sripanidkulchai [16] caches query results independently from the node that made the query, which, in return, may result in delivering incomplete query responses. Furthermore, our performance metrics completely differ from that used in [16]. While Sripanidkulchai [16] uses the traditional performance metric of ``hit rate'', we show that in Gnutella query result caching, ``hit rate'' is not well defined and alternative performance metrics need to be considered.
Gnutella query caching, can be viewed as an extension of web document caching [17] and of search engine query caching [11,9]. However, Gnutella query caching has significant differences from previous caching approaches including (i) different temporal locality characteristics, (ii) different performance benefits, and (iii) different staleness properties. For example, a search engine's query result can safely be cached for several hours (if not for days). On the contrary, Gnutella query results may easily become stale within a few minutes.
|
In our first experiment we report the number of the Gnutella query requests observed by each client. Table 1 shows the average number of queries received per second for each of the three clients. We immediately notice that all clients received a similar amount of query requests ranging between 46 and 52 requests per second. It is interesting to note that the geographic location of a client did not seem to have a direct effect on the number of queries it receives. For example, the US-based client (in Rochester) received less query requests per second than the client in Southern Europe (Crete). This is probably due to the time difference between Europe and the States, and/or because the topology of the Gnutella network does not necessarily follow that of the underlying geographical network, and therefore, clients that are geographically away from the United States may still receive a large amount of traffic. Figure 2 shows the actual number of queries received per second by each one of our three clients as a function of time. We immediately see that the load of each client varies very rapidly with time. For example, the query requests per second received by the client in Norway were between 1 and 585. That is, the client's load varied by as much as three orders of magnitude. Similarly, the load of the other clients as well varied 2-3 orders of magnitude.
|
To see if this burstiness of traffic holds over several time scales we plot the number of queries submitted per time interval (as a function of the time interval). 4 We use intervals of one second, 10 seconds, 1 minute, and 5 minutes. Figure 3 shows that for small intervals, (one and ten seconds) the traffic is very bursty and varies by as much as 2-3 orders of magnitude. The traffic remains bursty even for larger intervals (one minute and five minutes long), although the burstiness does not exceed one order of magnitude.
|
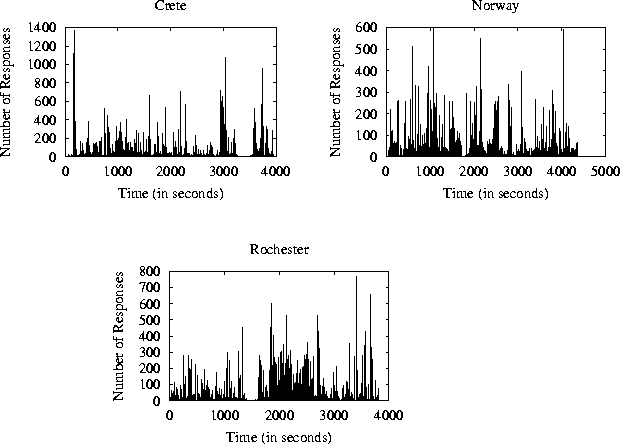
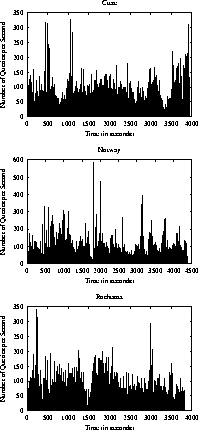
In our next experiment we investigate what are the traffic patterns that result from responses to Gnutella queries. Table 2 shows the average number of responses per second that were observed by each of our clients. We see that the client in Crete received more than 44 responses per second, the client in Rochester received 32 responses per second, and the client in Norway received 27 responses per second. Figure 4 plots the actual number of responses seen per second by each one of the clients. We immediately see that the traffic due to responses is very bursty. For example, there were times where the clients received more than 1,000 query responses within one second. These were responses to queries that matched a lot of files. For example, one of the most popular queries we encountered in our measurements was the query ``game'' that matched more than 7,000 files, including several computer games, as well as songs and images that happened to have the work ``game'' in their titles. 5
|
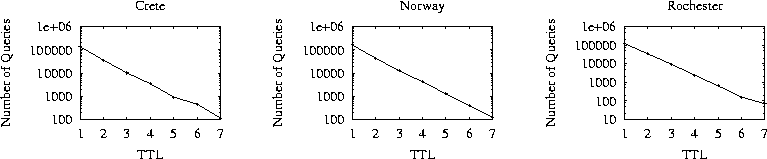
Although some queries produce a large number of responses, most queries produce no responses at all. Table 3 (second column labeled ``TTL>0'') shows the percentage of queries that produced at least one response (at least one hit). We see that this percentage is between 2.9% and 3.4% for all our clients. These low percentages is probably due to the fact that the clients we installed for measuring Gnutella traffic share no files, and therefore could not generate a reply to any query. Thus, all query requests that terminate in our clients (i.e. have a TTL equal to one), are not forwarded to their neighbors and do not generate any responses. To factor out the effects of our clients, we measured the number of responses as a percentage of the queries that had a TTL greater than one. Queries with TTL greater than one were not terminated by our clients - they were forwarded to other clients. Therefore, we removed the queries with TTL equal to one from our calculations and measured the responses to queries that had TTL greater than one. The resulting percentage is shown in the third column of table 3. We see that only 10%-12% from the queries (with TTL greater than one) had any responses. Even though this percentage is higher than the one measured over all queries, it is still very low: roughly speaking, nine out of ten queries generate no response.
To see if the burstiness of Query responses holds over several time scales, we plot the number of query responses received per time interval (as a function of the time interval) in figure 5. 6 We use intervals of one second, 10 seconds, 1 minute, and 5 minutes. We see that for small intervals, (one and ten seconds) the traffic is very bursty and varies by as much as 2-3 orders of magnitude. However, we see that the traffic remains bursty even for larger intervals (one-minute and five-minute intervals). Similar observations about the burstiness of Internet traffic have been reported before for the Internet and the web [4,8].
|
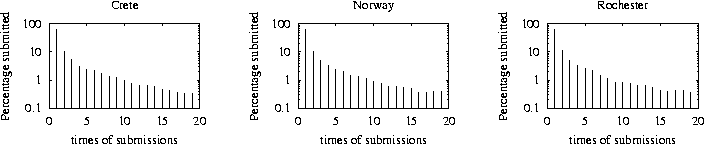
Table 4 shows the average number of times each query has been observed by our probes. The second column (labeled ``TTL > 0'') shows the average for all queries, and the third column shows the average for queries that have TTL greater than one. The latter are queries that are forwarded to other clients. We see that the average number of submissions of each query is between 4.5 and 5 (over all queries), and between 2.6 and 3 (for queries with TTL greater than one). Figure 8 shows the percentage of queries that were submitted only once, the percentage of queries submitted twice, and so on. We see that in all cases, 60% of the queries were submitted only once, and therefore about 40% of the queries were submitted more than once. Actually, about 10% of the queries were submitted twice, 5% of the queries were submitted three times, and so on. It is interesting to see that these percentages are almost identical for all clients.
Table 4 has already established that Gnutella query requests exhibit a significant amount of locality. In our next experiments we explore whether this locality can be exploited in order to reduce the overall network traffic. Locality is usually exploited (among other ways) by caching of the frequently accessed data. For example, web-caching and content delivery systems store copies of frequently-accessed data in proxies (caches) located close to the clients that request them [17].
However, caching query results in peer-to-peer systems, like Gnutella, is significantly different from caching (query results or other documents) in web caching systems. The main difference between Gnutella caching and web caching is that in traditional web caching, the ``content'', that is cached by proxies, is provided by well-defined web servers. On the contrary, in Gnutella, the ``content'' (which is actually the sum of the responses to a query request) is not provided by any well-defined single server, but is computed by composing the results of the content provided by several peers. Therefore, besides the peer that originally issued the query, no other peer has complete knowledge of the ``content'' of a query's response.
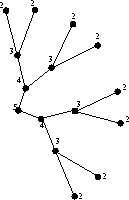
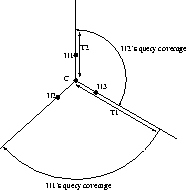
Let us illustrate the difference between web caching and peer-to-peer caching by an example shown in Figure 9: suppose that a Gnutella peer C receives a query request (e.g. ``cnn'') from its neighbor N1 with TTL equal to T1. C forwards the query to neighbors N2 and N3, and receives the query's responses which it later forwards to N1. The responses that C has collected represent all the files that matched ``cnn'', and are reachable within T1 hops from C through its neighbors N2 and N3. Suppose now, that at some later point in time, C receives the same query request (``cnn'') from neighbor N2 with TTL equal to T2. In this case, C can not just give to N2 the results of N1's query request, because they do not include the files that match ``cnn'' that are reachable through N1. Furthermore, since the TTL's of the two queries are different, the responses to each query correspond to a different coverage of the Gnutella network. Therefore, C can not just use the response of the N1's query to satisfy N2's query, even though the two query requests textually match each other. Thus, although a Gnutella peer may see a query request several times, these requests do not necessarily produce the same results, especially if they originate from different neighbors and have different TTLs. Therefore, Gnutella caching systems need to take into account not only the text of the query request but also the query's TTL, the neighbor that issued the request, and in general, all the factors that define the coverage of a query's response.
Although Gnutella Caching is different from web caching, it can still be employed in order to improve performance. Our proposed approach to Gnutella caching is as follows: When a client C receives a query from neighbor N2, its checks its cache to see if a query with the same text and the same TTL has been seen in the past. If such a query if found, and if this query has been sent in the past by neighbor N2, C returns the responses that exist in its cache for this query. If, on the other hand, C finds such a query in its cache, but the (cached) query had been sent by neighbor N1, C forwards the (new) query to N1, receives the results, combines them with the locally cached results of the query, and forwards the combined result to N2. 8
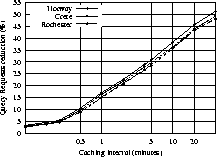
Figure 10 plots the reduction of the query request packets sent out in the network as a function of the caching interval. We see that caching query results even for as low as one minute reduces query request packets by as much as 15%-20%. Caching for 5 minutes results in a 30% reduction. Caching for half-an-hour results in close to 50% network traffic reduction. Effectively, caching query results for 30 minutes reduces the number of query requests by half. Our results agree with the query popularity patterns observed in table 4. For example, table 4 suggests that each query (with TTL > 1) is submitted on the average close to 2.5 times. Therefore, an ideal caching algorithm (that would cache queries indefinitely, and that would not take into account the sender of the query) could achieve a ``hit rate'' and an associated query request packets reduction of about 1.5/2.5=60%. Our simulations suggest that by using our less-than-ideal caching approach and by caching Gnutella query response for half an hour results in a query request packets reduction close to 50%, which is close to the ``ideal'' 60%.
Although caching reduces network traffic significantly, it requires that each peer contributes an amount of its local memory to store the cached query responses. If the size of this local memory (hereafter called the cache size) turns out to be large, it can be a limiting factor to the deployment of caching. This cache size includes the memory needed to store the query responses themselves, as well as all the metadata need to organize these responses into appropriate and efficient data structures. The reader may notice that this cache size may vary with time, because the proposed Gnutella caching approach keeps the responses of only the last given time interval, and as shown in figure 4 the number of these responses may vary. Therefore, during a busy time interval, the cache size will be larger than it would be during a low-traffic time interval. To smooth these fluctuations, our results report the average amount of memory needed for the duration of the simulation. Figure 11 plots the average cache size as a function of the caching interval. We immediately see that the memory demands are very low. For example, caching query responses (and their associated metadata) for one minute required only 200 KBytes. Caching query responses for as long as five minutes required no more than 1 MByte of memory. Even caching for as long as 20 minutes required no more than 3 MBytes of memory. Therefore, the memory needs of Gnutella caching can be considered rather small. Most (if not all) Gnutella peers can easily invest a few hundred KBytes (or at most a few MBytes) of their memory in order to improve performance, and reduce the overall network traffic.
Overall, we believe that peer-to-peer caching systems are beneficial today and will be increasingly important in the near future when an even larger number of will join peer-to-peer networks.
This document was generated using the LaTeX2HTML translator Version 98.1p1 release (March 2nd, 1998)
Copyright © 1993, 1994, 1995, 1996, 1997, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -debug -split 0 paper.tex.
The translation was initiated by Evangelos Markatos on 2002-06-01