The Internet carries information in packets
whose size varies from 40 bytes to a few Kilobytes.
Similarly, variable-size packets are used
in the majority of communication across the whole spectrum
from WAN, MAN, LAN, and cluster interconnects to
storage, server, computer I/O, processor-memory interconnects,
embedded systems, and networks-on-a-chip.
These ubiquitous networks are formed by interconnecting
switches or routers, which, in turn, are usually built
around a crossbar switch at their core.
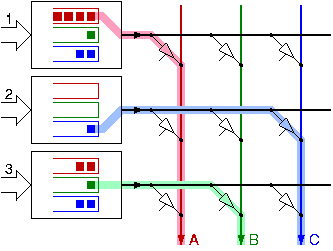 Crossbars allow multiple, simultaneous transfers of information,
as shown in figure 1, on the right,
and have thus replaced old-time buses
which precluded any such parallelism.
Crossbars allow multiple, simultaneous transfers of information,
as shown in figure 1, on the right,
and have thus replaced old-time buses
which precluded any such parallelism.
Switches and routers contain buffer memories in order to temporarily hold packets during output contention. Figure 1 shows a 3x3 switch with buffer memories at the inputs, as in the usual contemporary architectures. Each of the 3 input buffers holds packets in 3 per-output queues, based on each packet's destination; these are often called virtual output queues (VOQ). At each given time, a crossbar is configured to pair-up one specific input to each given output (highlighted paths in fig. 1). Choosing a "good" configuration is crucial and complicated: some configurations are inefficient (e.g. not pairing up output C to input 2 in the figure), while others may be unfair. Furthermore, crossbar configurations must be changed frequently, in response to the pattern of arriving packets, in order to serve all traffic flows and achieve low delays.
When the crossbar configuration is changed, it is very hard not to change all input-output parings at once. This is the reason why contemporary crossbars operate on fixed-size cells: a configuration is held for the time it takes to transfer one cell across each path, and is then changed for the next cell-time. But then, how can we route variable-size packets? The method used is to segment them into fixed-size cells, get the cells through the crossbar, and then reassemble the original packets at the router outputs.
Segmentation and reassembly (SAR) introduces inefficiencies. Consider the example of a 1-GByte/s system using 64-byte cells. At 1 GB/s (1 byte/ns), 64 bytes (=1 cell) arrive in 64 ns. However, if 65-byte packets arrive back-to-back they must be handled in 65 ns each; given that they each require 2 cells, the system must be able to handle each cell in 32.5 ns, i.e. an effective rate requirement about twice the link rate. To make things worse, crossbar schedulers --the circuits that must find the next crossbar configuration-- are imperfect, because they try to solve a complex problem within just a few tens of nanoseconds. To compensate for these scheduler inefficiencies, the crossbar must switch cells faster than their rate of arrival --e.g. within 20 to 25 ns, rather than 32.5 ns, in the above example. This ratio of the crossbar speed relative to the line rate (equal to 65 over 20 or 25 in our example) is called the crossbar speedup factor. Commercial products use speedups in the range of 3, meaning that their crossbars are about 3 times faster than line rate. Conversely phrased, the fastest lines that can be handled are about three times slower than the fastest crossbar that can be built!
Distributed Scheduling
In the last 5 years, a new crossbar architecture has been studied that improves scheduling efficiency. Observe carefully figure 1, above: the scheduling problem for each output consists of sequentially selecting packets of its "color" from the various inputs that have such. However, these selections all depend on each other! At every given time, no two outputs are allowed to select packets from the same input. The key of the new architecture is to relax this dependency requirement. Over the long term, the dependency cannot be eliminated, because line or buffer throughput rates would be violated. However, we can convert the dependency requirements from their form of balanced instantaneous rates into a form of balanced average rates over a sliding time window.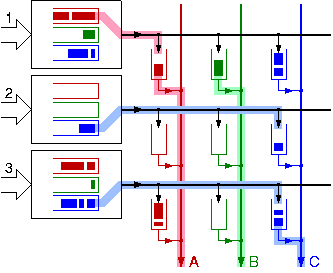 To achieve this, we need to place
small buffer memories at each crosspoint, as shown in figure 2;
the size of these buffers determines the width of the averaging window.
The new architecture is called Buffered Crossbar
or Combined Input-Crosspoint Queueing (CICQ);
it is becoming feasible today because of advances in CMOS technology
that allow the integration of several MBytes of RAM
inside crossbar chips.
To achieve this, we need to place
small buffer memories at each crosspoint, as shown in figure 2;
the size of these buffers determines the width of the averaging window.
The new architecture is called Buffered Crossbar
or Combined Input-Crosspoint Queueing (CICQ);
it is becoming feasible today because of advances in CMOS technology
that allow the integration of several MBytes of RAM
inside crossbar chips.
In this new architecture, each output scheduler chooses to forward traffic from one of the non-empty buffers in its column; the choices are independent: both outputs A and B, in fig. 2, forward packets that originated from input 1, which was not feasible in the old architecture. Similarly, each input scheduler independently chooses to forward traffic to one of the non-full buffers in its row (e.g. both inputs 2 and 3 forward blue packets). Of course, in the long run, choices become dependent, because some buffers will empty and others will fill-up thus indirectly coordinating the scheduler decisions. This CICQ architecture allows much simpler and very efficient crossbar scheduling, thus removing one of the two reasons for using the crossbar speedup that was discussed above. Our work of 2001-2002 on this topic dealt with the ability of this simpler and efficient crossbar scheduling to provide weighted max-min fairness and can be found at http://archvlsi.ics.forth.gr/bufxbar/bxb_scheduling.html
Variable-Size Packets
The next and most interesting observation, in the last couple of years, is that this new architecture is also capable to operate directly on variable-size packets, without segmentation and reassembly (SAR). Given that schedulers are independent of each other, there is no requirement for all of them to change from one configuration to the next in synchrony, hence there is no need for a single, common, fixed cell size. This observation radically changes the entire system.When SAR is eliminated, the other of the two reasons for using crossbar speedup also disappears. Hence, the new switches can handle line rates as fast as the fastest crossbar that can be built, i.e. line rates about three times higher than with the old crossbars, based on the above discussion of speedup factor. Another gain is the elimination of output buffer memories: in switches with speedup, the crossbar is faster than the outputs over periods of time when scheduling and packet sizes are favorable. Then, cells accumulate at the outputs and have to be buffered; buffers are also needed for the reassembly of packets from cells. With the elimination of both SAR and speedup, there is no reason to have output buffers, either, thus greatly reducing cost.
FORTH is one of the very few pioneers who investigate this new architecture and advocate its adoption. In our research group on Packet Switch Architecture (about 8 people), in the Institute of Computer Science, FORTH, Crete, Greece, we are now completing the design and layout of a buffered crossbar CMOS chip, containing roughly 150 million transistors, that directly switches variable-size packets. Using detailed simulations, we have already verified both the correctness of the design and the excellent performance characteristics of the architecture. We are now adapting the line card (VOQ) organization for variable-packet-size operation. Our results can be found at http://archvlsi.ics.forth.gr/bufxbar/
| Up to Buffered Crossbar R&D at FORTH | © copyright 2004 by FORTH
Last updated: Feb. 2004, by M. Katevenis. |