OUTLINE:
The crossbar is the most frequently used switching element topology. It offers simplicity and non-blocking operation. However, when bufferless, it also requires a centralized scheduler, which must simultaneously satisfy --in each cell time-- all input and all output link constraints. The cost and complexity of this scheduler increases considerably for short cell times and for large switch sizes; additionally, these schedulers cannot practically offer WFQ-type QoS. Furthermore, bufferless crossbars were considered to only efficiently operate with fixed-size cells arriving from mutually-synchronized line cards; when needing to switch variable-size packets, existing systems first segment them into fixed-size cells. To compensate for the inefficiencies of scheduling and of packet segmentation, internal (crossbar) speedup is used; commercial crossbars often use a speedup factor of 2 to 3. The net effect is to limit the maximum external line rate to roughly one half to one third the peak achievable crossbar line rate.
The operation of the crossbar can be dramatically improved by including small buffers at each crosspoint; CMOS technology has recently reached the point where this is feasible for the buffer sizes that are needed in order for backpressure flow control to operate efficiently between the crossbar and the VOQ's in the ingress line cards. This "buffered crossbar" or "combined input-crosspoint queueing (CICQ)" architecture has significant advantages over the previous, traditional bufferless configuration:
- The scheduling task is dramatically simplified; WFQ-type QoS is easily implementable; there are no scheduler inefficiencies to be compensated by speedup.
- The crossbar can operate directly on variable-size packets, hence there is no need for segmentation and reassembly circuits; the need for mutually synchronized line cards (at the cell-time level) is also eliminated.
- Internal speedup is not needed, because there is no packet segmentation and no scheduler inefficiencies; hence, the external line rate can be as high as the crossbar line rate.
- The egress path of the switch needs no buffer memory --at least no large, off-chip memory-- because packet reassembly is not needed, and because, in the lack of internal speedup, there is no output queue build up; this eliminates a major cost component.
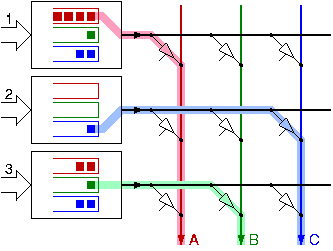
In a bufferless crossbar, the scheduling decisions at the input and output ports all depend on each other: each output can only be paired to a single input and conversely for the inputs |
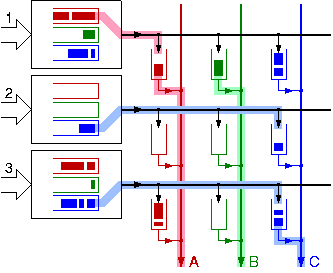
Small buffer memories at the crosspoints allow distributed scheduling decisions; operation with variable-size packets now becomes feasible |
For an introductory explanation page, for the non-specialist, click here.
We have studied scheduling, including extensive studies of WFQ-type scheduling, in cell-based CICQ switches; see section 1 below. We have also studied the implementation of multiple priority levels in buffered crossbar (CICQ) switches; see section 4 below. Then we studied the design and detailed operation of buffered crossbars operating directly on variable-size packets; see section 3 below. Recently, we have observed that even bufferless (input-queued, IQ) crossbar switches can be asynchronously scheduled, and thus can directly operate on variable-size packets; see section 2 below.
1. Distributed Scheduling in Buffered Crossbars
The scheduling task is dramatically simplified in buffered crossbars: distinct servers at each input and each output collectively but still independently schedule the set of flows through the interconnect; they are loosely coordinated through backpressure signals from the crosspoint buffers.1.1 WFQ Distributed Scheduling in Buffered Crossbars (2002-2003)
We have analyzed such distributed scheduling policies in buffered crossbars operating on fixed-size cells and using weighted fair queueing (WFQ) schedulers at each input and output. Our results are presented in several papers, available through another page: please click on section 1.1 title, above.1.2 Credit Prediction for Minimally-Sized Crosspoint Buffers (2005-2007)
- Preprint of April 2007 available in PDF (XXX KBytes); © Copyright 2007 by IEEE.
-
ABSTRACT:
To be filled in....
2. Asynchronous Operation of Bufferless Crossbars
- Preprint of April 2007 available in PDF (130 KBytes) or Postscript (320 KBytes); © Copyright 2007 by IEEE.
- Presentation Slides in PDF (190 KBytes); © Copyright 2007 by FORTH.
-
ABSTRACT:
It is widely believed that bufferless crossbar switches
with virtual-output queues (VOQ) at their inputs can only operate
when their input-output connections are reconfigured in synchrony,
i.e. only under fixed-size cell traffic.
Packet-mode scheduling has been studied, but, again,
assuming that all packets consist of an integer number of cells,
where the scheduling time coincides with the cell time.
We show that bufferless crossbars can operate
directly on variable-size packets,
with input-output connections being made and torn down
asynchronously with respect to each other.
Although such operation can initially be thought of
as an extension of packetmode scheduling,
the critical difference is that now the scheduling time
is much longer than packet-size granularity.
We study a transformation of the well-known iSLIP scheduling algorithm
to asynchronous mode of operation,
and we show by simulation that it can be adapted
to yield throughput close to 100% under a range of workloads.
The overall result is an efficient scheduling operation,
with the added advantages of eliminating
(a) packet fragmentation overhead (no partially filled cells), and
(b) packet reassembly in the egress datapath.
3. Variable-Packet-Size Buffered Crossbars
Buffered crossbars can directly switch variable-size packets, thus eliminating SAR and egress buffers (both for queueing and for packet reassembly) altogether; this was studied in our papers of section 3.1, below. There is, however, a cost associated with this solution: the size of each crosspoint buffer is linked to the maximum size of the (variable-size) packets. To solve this problem, while at the same time drastically reducing the header overhead of small packets, we proposed variable-size multipacket segmentation, as described in our papers of section 3.2, below.3.1 Variable and full size (unsegmented) packets (2003-2004)
- Preprint in PDF (250 KBytes) or Postscript (540 KBytes); © Copyright 2004 by IEEE.
- Talk Transparencies in PPT (290 KBytes) or PDF (205 KBytes); © Copyright 2004 by FORTH.
-
ABSTRACT:
One of the most widely used architectures
for packet switches is the crossbar.
A special version of it is the buffered crossbar,
where small buffers are associated with the crosspoints;
this simplifies scheduling
and improves its efficiency and QoS capabilities
to the point where the switch needs no internal speedup.
Furthermore, by supporting variable length packets
throughout a buffered crossbar:
(a) there is no need for segmentation and reassembly (SAR) circuits;
(b) no speedup is necessary to support SAR; and
(c) synchronization between the input and output clock domains
is simplified.
In turn, the lack of SAR and speedup
mean that no output queues are needed, either.
In this paper we present an architecture,
a chip layout and cost analysis, and a performance evaluation
of such a 300 Gbps buffered crossbar
operating on variable-size packets.
The proposed organization is simple yet powerful,
can be implemented using modern technology, and,
as the performance results demonstrate,
it clearly outperforms unbuffered crossbars.
[Previous, outdated version: Sep. 2003, 8 pages, in pdf (140 KB) or ps (310 KB)].
- Available in PDF (1.15 MBytes) format; © Copyright 2004 FORTH.
-
This technical report gives the details of the design of the chip
described in the above paper
"Variable Packet Size Buffered Crossbar (CICQ) Switches".
In particular,
we present the design, using a hierarchical ASIC flow,
of a 32x32 buffered crossbar chip core,
operating directly on variable-size packets
using a 2 KByte 2-port SRAM buffer in each of the 1024 crosspoints,
and providing 300 Gb/s of aggregate bandwidth
in 0.18-micron CMOS technology.
In this technology,
core area is 420 square mm, and core power is 6 W;
extrapolations for 0.13-micron CMOS indicate an estimated
core area of 200 square mm, and core power of 3.2 W.
The majority of core power is consumed in driving cross-chip wires,
while memories and logic are minority consumers.
Hierarchical ASIC flows are difficult to use,
but became necessary due to the large size of the design.
We present the detailed system design
(block diagrams as well as critical circuit details),
followed by a description of the design flow,
including its numerous intricacies and the lessons that we learnt.
In particular, we describe the choice of a hierarchy that is
appropriate for effective placement, routing, and timing behavior.
The final placement and routing showed that
the synthesis tool had underestimated the design area by 30%,
due to the dominance of long (end-to-end) wires in this design.
- Available in PDF (350 KBytes) or Postscript (1.2 MBytes) format; © Copyright 2003 FORTH.
-
This technical report describes in more detail
the simulator used for the performance evaluation in the above paper
"Variable Packet Size Buffered Crossbar (CICQ) Switches".
It also contains additional simulation results.
3.2 Variable-size multipacket segmentation (2005-2006)
- Preprint in PDF (200 KBytes) or Postscript (300 KBytes); © Copyright 2005 by IEEE.
-
ABSTRACT:
Buffered crossbars can directly switch variable size packets,
but require large crosspoint buffers to do so,
especially when jumbo frames are to be supported.
When this is not feasible,
segmentation and reassembly (SAR) must be used.
We propose a novel SAR scheme for buffered crossbars
that uses variable-size segments
while merging multiple packets (or fragments thereof)
into each segment.
This scheme eliminates padding overhead,
reduces header overhead, reduces crosspoint buffer size
and is suitable for use with external, modern DRAM buffer memory
in the ingress line cards.
We evaluate the new scheme using simulation,
and show that it outperforms existing segmentation schemes
in buffered as well as unbuffered crossbars.
We also study how the size of the maximum segment
affects system performance.
[Previous, outdated version: Aug. 2004, 6 pages, in pdf (200 KB) or ps (300 KB)].
- Preprint in PDF (150 KBytes) or PostScript (350 KBytes); © Copyright 2006 by IEEE.
-
ABSTRACT:
Buffered crossbars have emerged
as an advantageous switch architecture
mainly due to their scheduling efficiency
and capacity to operate directly on variable size packets.
Such operation requires crosspoint buffers
at least as large as one maximum packet each.
When we cannot afford that large crosspoint buffers,
we are forced to segment packets.
Although variable-size segments
can be used to avoid padding overheads,
we are still left with the cost of reassembly buffers
and the associated delays.
This paper applies
packet mode scheduling to buffered crossbars
in order to remedy these shortcomings:
the segments of a variable-size packet
are switched consecutively in time.
We propose two scheduling schemes:
probabilistic and deterministic
packet mode scheduling.
The probabilistic case allows cut-through forwarding
and operates with independent crossbar output schedulers,
but it requires reassembly buffers.
Deterministic scheduling sacrifices some scheduler independence
in order to eliminate the reassembly buffers.
Using simulation we show that it performs
very close to buffered crossbars with no segmentation
and large buffers at the crosspoints.
[Previous, outdated version: Oct. 2005, 6 pages, in PDF (180 KBytes)].
4. Multiple Priority Levels in Buffered Crossbars (2003-2004)
- Preprint in PDF (280 KBytes) or Postscript (370 KBytes); © Copyright 2004 by IEEE.
-
ABSTRACT:
A significant advantage of buffered crossbar
(combined input-crosspoint queueing - CICQ) switches
is that they can directly operate on variable-size packets,
thus saving the costs and inefficiencies
of packet segmentation and reassembly (SAR).
However, in order to support multiple priority levels,
separate queues per priority are needed at each crosspoint,
in order to prevent HOL blocking and buffer hogging;
these queues are expensive
because they each need a size of at least one maximum-size packet.
In this paper we propose a scheme
that uses only two queues per crosspoint
to effectively support multiple priorities.
We adaptively adjust the priority levels of the two queues
so that most traffic goes through the ``lower'' queue,
while the ``upper'' queue remains usually available
for higher priority packets to overtake the former.
Through simulation, and assuming 8 priority levels,
we compare our scheme
to an ideal system that uses 8 queues per crosspoint.
For realistic traffic,
the two systems perform almost identically,
although ours uses 4 times less memory in the crossbar.
Even under a highly irregular traffic pattern Bursts60,
our system will not increase the average delay of any priority level
by more than 75 percent compared to the ideal system.
[Previous, outdated versions: March 2004, 7 pages, in pdf (285 KBytes) or ps (330 KBytes); Sep. 2003, 8 pages, in pdf (300 KB) or ps (400 KB)].
- Available in PDF (850 KBytes) or Postscript (1.4 MBytes) format; © Copyright 2003 FORTH.
-
This technical report describes in more detail
the methods proposed in the above paper
"Multiple Priorities in a Two Lane Buffered Crossbar".
It also contains additional simulation results.
Further on, it presents the RS method,
which reduces the complexity in the ingress line-cards
and also reduces the HOL blocking and buffer hogging behavior.
Finally, it considers several design issues
related to variable-packet-size buffered crossbars:
alternative positions for the input schedulers,
storage of credits within the credit chip,
scheduling of operations at the contention points,
cut-through, store-and-forwarding, and
crosspoint buffers dimensioning.
Financial support was provided in part by the European Union FP6 IST Programme, under projects 002075 "SIVSS" STREP and 027648 "SARC" IP, and under the HiPEAC Network of Excellence. The CAD tools for chip design were provided by the University of Crete, through Europractice. Georgios Sapountzis helped us shape our ideas; we deeply thank him. We also acknowledge the assistance of V. Papaefstathiou, A. Ioannou, C. Georgis, C. Sotiriou, and S. Lyberis.
© Copyright 2003-2007 by IEEE or FORTH:
These papers are protected by copyright. Permission to make digital/hard copies of all or part of this material without fee is granted provided that the copies are made for personal use, they are not made or distributed for profit or commercial advantage, the IEEE or FORTH copyright notice, the title of the publication and its date appear, and notice is given that copying is by permission of the IEEE or of the Foundation for Research & Technology -- Hellas (FORTH), as appropriate. To copy otherwise, in whole or in part, to republish, to post on servers, or to redistribute to lists, requires prior specific written permission and/or a fee.