
Institute of Computer Science (ICS)
Foundation for Research & Technology - Hellas (FORTH), Crete
P.O.Box 1385
Heraklio, Crete, GR-711-10 GREECE
markatos@ics.forth.gr
http://www.ics.forth.gr/proj/avg/telegraphos.html
Evangelos P. Markatos and Manolis G.H. Katevenis
and Penny Vatsolaki
Modern networks of workstations connected by Gigabit networks have the ability to run high-performance computing applications at a reasonable performance, but at a significantly lower cost. The performance of these applications is usually dominated by their efficiency of the underlying communication mechanisms. However, efficient communication requires that not only messages themselves are sent fast, but also notification about message arrival should be fast as well. For example, a message that has arrived at its destination is worthless until the recipient is alerted to the message arrival.
In this paper we describe a new operation, the remote-enqueue atomic operation, which can be used in multiprocessors, and workstation clusters. This operation atomically inserts a data element in a queue that physically resides in a remote processor's memory. This operation can be used for fast notification of message arrival, and for fast passing of small messages. Compared to other software and hardware queueing alternatives, remote-enqueue provides high speed at a low implementation cost without compromising protection in a general-purpose computing environment.
Popular contemporary computing environments are comprised of powerful workstations connected via a network which, in many cases, may have a high throughput, giving rise to systems called workstation clusters or Networks of Workstations (NOWs) [1]. The availability of such computing and communication power gives rise to new applications like multimedia, high performance scientific computing, real-time applications, engineering design and simulation, and so on. Up to recently, only high performance parallel processors and supercomputers were able to satisfy the computing requirements that these applications need. Fortunately, modern networks of workstations connected by Gigabit networks have the ability to run most applications that run on supercomputers, at a reasonable performance, but at a significantly lower cost. This is because most modern Gigabit interconnection networks provide both low latency and high throughput. However, efficient communication requires that not only messages themselves are sent fast, but also notification about message arrival should be fast as well. For example, a message that has arrived at its destination is worthless until the recipient is alerted to the message arrival.
In this paper we present the Remote Enqueue atomic operation, which allows user-level processes to enqueue (short) data in remote queues that reside in various workstations in a cluster, with no need for prior synchronization. This operation was developed within the Telegraphos project [18], in order to provide a fast message arrival notification mechanism. The Telegraphos network interface provides user applications with the ability to read/write remote memory locations, using regular load/store instructions to remote memory addresses. Sending (short) messages in Telegraphos can be done by issuing one or more remote write operation, which eliminates traditional operating system overheads that used to dominate message passing. Thus, sending (short) messages can be done from user-level by issuing a few store assembly instructions. Although sending a message can be done fast, notifying the recipient of the message arrival may take significant overhead. For example, one might use a shared flag in which the sender writes the memory location (in the recipient's memory) where the message was written. When the recipient checks for messages, it reads this shared flag and finds out if there is an arrived message and where it is. However, if two or more senders attempt to send a message at about the same time, only one of them will manage to update the flag, and the other's update will be lost. A solution would be to have a separate flag for each possible sender. However, if there are several potential senders, this solution may result in significant overhead for the receiver, who would be required to poll too many flags. Arranging the flags in hierarchical (scalable) data structures might reduce the polling overhead, but it would increase the message notification arrival overhead.
Our solution to the message arrival notification problem is to create a remote queue of message arrival notifications. A remote queue is a data structure that resides in the remote node's main memory. After writing their message to the receiver's main memory, senders enqueue their message arrival notifications in the remote queue. Receivers poll their notification queues to learn about arrived messages. Although enqueueing notifications in remote queues can be done completely in software, we propose a hardware remote enqueue operation that atomically enqueues a message notification in a remote queue. The benefits of our approach are:
The rest of the paper is organized as follows: Section 2 surveys previous work. Section 3 presents a summary of the Telegraphos workstation cluster. Section 4 presents the remote enqueue operation, and section 5 summarizes this paper.
Although networks of workstations may have an (aggregate) computing power comparable to that of supercomputers (while costing significantly less), they have rarely been used to support high-performance computing, because communication on them has traditionally been very expensive. There have been several projects to provide efficient communication primitives in networks of workstations via a combination of hardware and software: Dolphin's SCI interface [19], PRAM [24], Memory Channel [13], Myrinet [6], ServerNet [26], Active Messages [12], Fast Messages [17], Galactica Net [16], Hamlyn [9], U-Net [27], NOW [1], Parastation [28], StarT Jt [15], Avalanche [10], Panda [2], and SHRIMP [4] provide efficient message passing on networks of workstations based on memory-mapped interfaces. We view our work as complimentary to these projects, in the sense that we propose a fast message notification mechanism that can improve the performance of all these message passing systems.
Brewer et. al proposed Remote Queues, a communication model that is based on enqueueing and dequeuing information in queues in remote processors [8]. Although their model is mostly software based, it can be tuned to exploit any existing hardware mechanisms (e.g. hardware queues) that may exist in a parallel machine. Although their work is related to ours we see two major differences:
In single-address-space multiprocessors, our remote enqueue operation can be completely implemented in software using any standard queue library. Brewer et. al propose such an implementation on top of the Cray T3D shared-memory multiprocessor [8]. Any such implementation (including the one in [8]) suffers from software overhead that includes at least one atomic operation (to atomically get an empty slot in the queue), plus several remote memory accesses (to place the data in the remote queue and update the remote pointers). This overhead is bound to be significant in a Network of Workstations.
In many multiprocessors, nodes have a network co-processor. Then, the remote enqueue operation can be implemented with the help of this co-processor. The co-processor implements sophisticated forms of communication with the processes running on the host processor. For example, a process that wants to enqueue a message in a remote queue, sends the message to the co-processor, which forwards it to the co-processor in the remote node, which in turn places the message in the remote queue. Although the existence co-processors improves the communication abilities of a node, it may result (i) in software overhead (after all they are regular microprocessors executing a software protocol), and (ii) in increased end-system cost.
The Remote enqueue operation described in this paper
is developed within the Telegraphos project [22].
Telegraphos is a distributed system that consists of network
interfaces and switches for efficient support of parallel and
distributed applications on a workstation cluster.
We call this project Telegraphos or
![]() from the greek words
from the greek words
![]() meaning remote,
and
meaning remote,
and
![]() meaning write, because
the central operation on Telegraphos is the remote write operation.
A remote write operation is triggered by a
simple store assembly instruction, whose argument is a (virtual) memory
address mapped on the physical memory of another workstation.
The remote write operation makes possible the (user-to-user, fully protected)
sending of short messages with a single instruction.
For comparison, traditional workstation clusters connected via FDDI and ATM
take several thousands of instructions to send even the shortest message
across the network.
Telegraphos also provides remote read operations,
DMA operations,
atomic operations (like
fetch_and_increment) on remote memory locations, and
a non-blocking fetch(remote,local) operation that
copies a remote memory location into a local one. Finally,
Telegraphos also provides an eager-update multicast mechanism which
can be used to support
both multicasted message-passing, and update-based
coherent shared memory.
meaning write, because
the central operation on Telegraphos is the remote write operation.
A remote write operation is triggered by a
simple store assembly instruction, whose argument is a (virtual) memory
address mapped on the physical memory of another workstation.
The remote write operation makes possible the (user-to-user, fully protected)
sending of short messages with a single instruction.
For comparison, traditional workstation clusters connected via FDDI and ATM
take several thousands of instructions to send even the shortest message
across the network.
Telegraphos also provides remote read operations,
DMA operations,
atomic operations (like
fetch_and_increment) on remote memory locations, and
a non-blocking fetch(remote,local) operation that
copies a remote memory location into a local one. Finally,
Telegraphos also provides an eager-update multicast mechanism which
can be used to support
both multicasted message-passing, and update-based
coherent shared memory.
Telegraphos provides a variety of hardware primitives which, when combined with appropriate software will result in efficient support for shared-memory applications. These primitives include:
The Telegraphos network interface has been prototyped using FPGA's; it plugs into the TurboChannel I/O bus of DEC Alpha 3000 model 300 (Pelican) workstations.
We propose a new atomic operation, the remote enqueue (REQ) atomic operation. The REQ atomic operation is invoked with two arguments:,
.
We define a remote queue to be a portion of a remote processor's memory that is managed as a FIFO queue. This FIFO queue is a linked list of buffers which are physically allocated in the remote processor's memory. Data are placed in this FIFO queue by the remote enqueue (REQ) operation, implemented in hardware. Data are removed from this FIFO queue with a dequeue operation which is implemented in user-level software.
The following limitations are imposed to the buffers of a remote queue, for the hardware remote enqueue operation to be efficient:
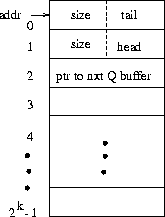
Figure 1: Layout of a data buffer. A remote queue is just
a linked list of such buffers.
The first three words of the buffer are reserved to store the
size, the tail, the head, and the pointer to the next Q buffer.
The layout of the buffer is shown in figure 1. The head and tail are indices in the data buffer. A queue is a linked list of such data buffers. For a 32-bit-word processor, both tail, and head are 16 bit quantities, and not full memory addresses. The reason is that, in traditional systems (where tail and head are full addresses), we calculate the pointer to the head (or the tail) of the queue by adding addr with head (or tail), meaning that we need to pay the hardware cost of an extra adder, and the performance cost of a word-length addition. In our system instead, where the addr is a multiple of a power of two, and both head and tail are always less than this power of two, we calculate the pointer to the head (or the tail) of the queue by performing an inexpensive OR operation instead of an expensive addition.
When processor A wants to enqueue some data in the remote queue vaddr that physically resides on processor B's memory, it invokes the REQ(vaddr,data) atomic operation. A portion of this operation in implemented on the sender node's network interface, and another portion of this operation is implemented on the receiver node's network interface.
When the software issues a REQ(vaddr,data) atomic operation, the local network interface takes the following actions:
When the destination node receives a remote-enqueue-request packet it extracts the paddr and data arguments from the packet and performs the remote-enqueue operation as the following atomic sequence of steps:
The hardware finite state machine (FSM) of the destination HIB for the remote enqueue operation ``req(addr, data)'' is shown in table 1.

Table 1: Finite State Machine for the Remote Enqueue Operation.
The Telegraphos datapath for the remote enqueue operation (at the receiver side) is shown in figure 2. The whole operation is controlled by five control signals: LD0, RD0, WR0, RD1, and WR1, that are generated by a simple Finite State Machine in the above order.
When the current buffer fills up, an interrupt is sent to the processor which starts executing the operating system. The actions that the operating system should take are:
In this section we outline how the dequeue operation can be efficiently implemented in software at user-level. A straightforward implementation of the dequeue operation would be:
deq(queue)
{
buffer = find_last_buffer_following_the_next_pointers() ;
if (is_empty(buffer) {
if (is_first(buffer, queue))
return EMPTY_QUEUE ;
else {
deallocate(buffer) ;
buffer = find_last_buffer_following_the_next_pointers() ;
}
}
result = buffer[head] ; head ++ ;
if (head == size)
head = 3 ;
return result
}
Unfortunately, the above solution does not always work, because it
is executed in user-space, and as such, it may
be interrupted at any time. For example, consider the
following scenario:
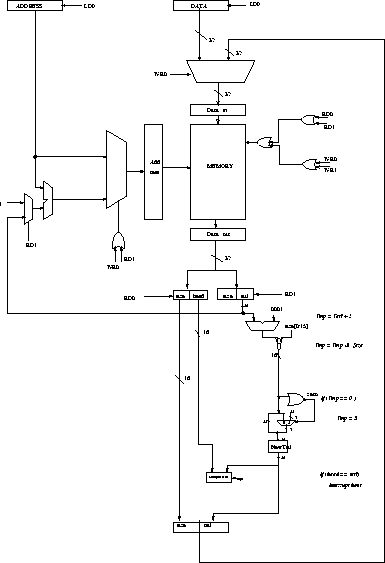
Figure 2: The enqueue hardware.
Fortunately, on the Alpha processor there is a special mode the PAL mode which enables (super) users to write their own code (of limited size) and run it uninterrupted [25]. Thus, if the above code is turned into PAL code, it will run uninterrupted. PAL code is invoked via the special cal_pal routine, that the DEC Alpha processor provides. Although any user is allowed to call a PAL function, only the super user is allowed to install new PAL functions, thereby protecting the integrity of the system. Thus, the above mentioned race conditions disappear because the dequeue operation runs uninterrupted in PAL mode.
Although PAL calls are an elegant way of executing
short sequences of instructions uninterrupted, they are specific
to the Alpha processor. Moreover, interrupt disabling (and of course PAL calls)
is an effective way of synchronization only in uniprocessors.
Disabling interrupts in symmetric multiprocessing systems
that share a common network interface does not necessarily guarantee the
absence of race conditions.
For this reason, we have developed a more general
solution that allows dequeue operations to proceed at user-level
without the need to invoke PAL calls. Our solution is based on the
collaboration between the operating system and the library that
implements the dequeue operation. We assume the existence of a
``do-not-preempt-me'' bit (per queue) that is shared by
the user application and
the kernel.
When the application is about to execute
a dequeue operation, it sets the ``do-not-preempt-me'' bit. When the
dequeue operation completes, it resets the ``do-not-preempt-me'' bit.
If the queue becomes full while an application is dequeuing something
from the queue, the operating system driver that handles the buffer overflow
interrupt, does not allocate a new buffer but sets a ``full-queue'' flag.
When the interrupt handler returns, the application will resume
execution, and it will complete the dequeue operation. When the
dequeue operation completes, it checks the ``full-queue'' flag.
If the flag is set, the application will invoke the network interface driver
(e.g. through an ioctl call) to allocate more space for the queue
and to enable the network interface to handle further enqueue operations.
This solution works even in multiprocessor workstations that share a
single network interface, with only one additional requirement: threads
that execute concurrent dequeue operations (from the same queue) have
to synchronize through a lock variable (associated with the queue).
The first instruction of a dequeue operation is to acquire the lock,
and the last instruction is to release the lock.
Thus, while a thread is dequeuing
data from a queue, no other thread is allowed to do the same, and
thus no other thread can access shared information
like the ``do-not-preempt-me'' bit and the
``full-queue'' flag.
In case of buffer overflow, user-level threads should keep the lock
up till the time the operating system allocates more space for the queue.
If the queue fills up while at the same time a thread is executing a dequeue
operation, the operating system allows the dequeue operation to complete;
after the operation completes it invokes the operating system to allocate
more space for the queue and to enable further network transactions.
An enqueue operation is invoked as:
enq(vaddress,data)
(where
vaddress
is the virtual address of the base of the first queue buffer
and
data
are the data to be enqueued).
In order to create a valid
remote enqueue request packet,
the network interface needs to know
the physical address paddr
that corresponds to virtual address
vaddr, as well as the data
argument.
However, users are not allowed to communicate physical addresses
to the network interface, because (i) they no dot know the
mapping between virtual and physical pages,
and (ii) malicious or ignorant users may request enqueue
operations to physical addresses on which
they do not have read/write access.
To alleviate this problem we use the mechanism of
shadow-addressing [5, 14, 23].
The method of shadow addressing
is used to securely translate virtual to physical addresses
and pass them to the
network interface from user-level processes.
For each virtual address vaddr that
is mapped in the physical address paddr, there is also
a shadow address shadow(vaddr), which is mapped in the
shadow physical address {shadow(paddr).
The shadow function is simple and known to the network interface.
One simple shadow function is to concatenate each address with an
extra shadow bit. When the shadow bit is set, then the address
is a shadow one.
For example, 0x0FFFFFFFF is a regular 33-bit address, while
0x1FFFFFFFF is its shadow address.
An access to a shadow address is always interpreted by the
network interface as a special argument passing operation.
For example, suppose that virtual address vaddr is mapped to
physical address paddr, and that the
virtual address shadow(vaddr) is mapped into shadow(paddr).
Normally, a load (store) operation to
virtual address vaddr by a user application
is translated by the TLB (page-table) into a load (store) operation to
physical address paddr and is performed by the appropriate memory
controller.
Similarly, a load (store) operation
to virtual address shadow(vaddr) is translated by the TLB into
a load (store) operation to physical address shadow(paddr).
When, however, this operation reaches the network interface it will be treated
as an argument passing operation, and neither a load nor a store
operation will be performed to physical address shadow(paddr).
Thus, when the user application wants to pass to the network interface
the physical address paddr, it makes a store operation to
virtual address shadow(vaddr). Eventually
the physical address shadow(paddr) reaches the
network interface, which recognizes the shadow address and takes the
physical address paddr by applying function shadow ![]() to physical address shadow(paddr).
to physical address shadow(paddr).
Thus, a remote enqueue atomic operation is issued using a single assembly instruction as follows:
REQ (vaddr, data)/* pass physical address shadow(paddr) to the
** network interface */
STORE data TO shadow(vaddr)
 Computer.
Cambridge, Massachusetts, February 1990.
Computer.
Cambridge, Massachusetts, February 1990.
The Remote Enqueue Operation on Networks of Workstations
This document was generated using the LaTeX2HTML translator Version 96.1 (Feb 5, 1996) Copyright © 1993, 1994, 1995, 1996, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -debug -split 0 paper.
The translation was initiated by Evangelos Markatos on Fri Dec 5 18:30:12 EET 1997