In our work we use remote main memory to store redundant information that will be used to recover from workstation crashes. Another approach would be to store all remote pages to the local disk as well [11], effectively treating remote memory as a write-through cache of the disk. We will now compare the two approaches to find out the circumstances under which the one approach is preferable to the other.
Both approaches use the remote memory to satisfy the read requests. This means that both approaches perform reads at the same speed and avoid disk head movements due to reads, thus outperforming the local disk. Parity logging transfers 1 + 1/N pages per paged out page, due to the parity computation (in our experiments N was equal to 4). On the other hand, write through transfers each paged out page both to disk to the remote memory. These two page transfers are executed in parallel. This means that the choice of the right approach depends on the effective bandwidth offered by the disk and the network. If the network bandwidth is much higher than the disk bandwidth, then the disk will be the bottleneck for write through making it an unwise choice. If however the effective bandwidth offered by the disk is comparable to the bandwidth offered by the network and the system can overlap disk transfers with network transfers then it is unclear which method is best to use. In our experimental environment the disk and network bandwidth are both equal to 10 Mbps. When write through is used the efective disk bandwidth is close to 10 Mbps, since there are no head movements for reads and writes are performed in large chunks. In this environment write through performs better than parity logging and slightly worse than our no-reliability implementation in most cases, as shown in figure 5 . However, when a modern high bandwidth network is used, parity logging will probably be the best approach, since write through will eventually be limited by the local disk bandwidth.
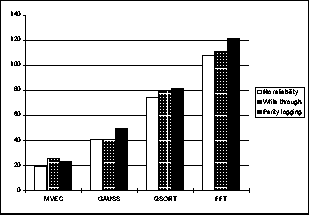
Figure 5: Performance of parity logging and write through for
various applications.
The input sizes for QSORT was 3000 records, for GAUSS, a
1700 ![]() 1700 matrix, for MVEC a 2100
1700 matrix, for MVEC a 2100 ![]() 2100 matrix, and for
FFT an array with 700 K elements.
2100 matrix, and for
FFT an array with 700 K elements.