Computer Architecture and VLSI Systems Division,
Institute of Computer Science (ICS), FORTH
Science and Technology Park of Crete,
P.O.Box 1385, Heraklion, Crete, GR 711 10 Greece
© copyright 1997 by FORTH, Crete, Greece
In order to provide advanced Quality of Service (QoS) architectures in high speed networks, Weighted Fair Queueing is needed. We have been working since 1985 on weighted fair queueing, i.e. on: (i) per-flow queueing, and (ii) weighted round-robin scheduling. The latter work includes hardware for heap (priority queue) management, for the case of arbitrary weight factors, and the scheduler presented here, for the case where weight factors are drawn from a small set of values.
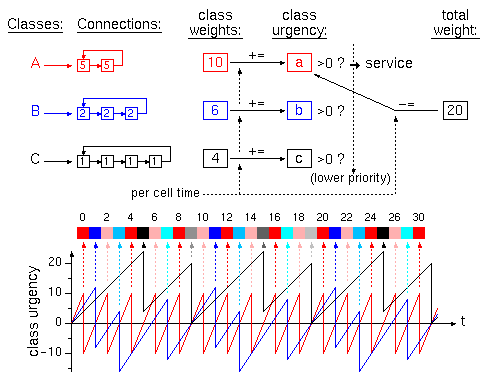
The operation of this scheduler is inspired by the computer graphics algorithm for drawing straight lines on a bit-mapped display, using only integer additions and subtractions: Express the slope of the line as a ratio of two integers, i/j; use a counter; advance horizontally, one bit at a time, adding i to the counter; when the counter grows positive, advance vertically by one bit, and subtract j from the counter. The operation of the scheduler is illustrated in the following figure.
In this example, three classes of flows (VC's) exist: classes A, B, and C. Each flow in class A has a weight factor of 5; flows in class B have a weight factor of 2, each, while those in C have a factor of 1. Assume that the unit of service is the same in each flow (one ATM cell in this example), hence flows inside each class are serviced in round-robin fashion. The total weight factor of all flows in class A is 10, in the above example; for class B this number is 6, and for class C it is 4. The scheduler maintains an urgency counter per class. During each service interval (one cell time here), the urgency counter of each class is incremented by its class weight, and one of the classes is chosen for service (see below); the urgency counter of the class that receives service is decremented by the total weight factor (the sum of all class weights) -- 20 in this example. Obviously, this means that the sum of all urgency counts remains constant (e.g. zero), as long as one flow (class) receives service during each service interval.
The class to be serviced is chosen among the classes whose urgency count is positive. The method of choice, has an impact on the service time jitter, as revealed by the simulations that we present below. We examined three methods of choosing among the classes with a positive urgency count: (i) choose the class with the highest urgency count; (ii) choose in a round-robin fashion among the classes with positive urgency counts; (iii) choose the highest priority class among the classes with positive urgency counts. (We also compared these to Zhang's "virtual clock" scheduling algorithm). Our measurements showed that choice (iii) leads to the smallest jitter: choose the highest priority class among the classes with positive urgency counts. Class priority is according to the weight factors of individual flows (A, then B, then C, in our example). The diagram at the bottom of the above figure pictorially shows how the three urgency counts would evolve with time, in this example, and which class (color) and flow (color tone) would receive service in each time unit (service interval).
The core of this scheduler (the urgency counter and decision logic) fits in a small FPGA like the Altera 10K10; with a 50 MHz clock, it can service 4 million events per second, which corresponds to an aggregate I/O line throughput of 1.6 Gbps in the case of scheduling ATM cells. Our design kept the per-class queues (circular lists) of VCs in an external SRAM, managed by a separate FPGA (the queue-manager FPGA).
We designed in detail and simulated a scheduler core for 8 classes of flows. In this design, the class weights and the total weight are 16-bit integers; the urgency counters are 24-bit integers. These weight and counter values are kept in 3 "Embedded Array Blocks" (EABs); an EAB is a 256x8-bit SRAM block inside the FPGA, in the Altera FLEX10K-family terminology. The EABs are partially filled, but we needed three of them for throughput rather than capacity reasons. Besides the 3 EABs, our scheduler core design used 143 flip-flops and 226 gates (average fan-in = 3.1), in 285 logic cells. When compiled into an Altera EPF10K10LC84-3 FPGA, the scheduler core uses 50% of the logic cells and 100% of the EABs, and operates up to 51 MHz. When compiled into an EPF10K40RC240-3 device, it occupies only 12% of the logic cells and 38% of the EABs, and operates up to 42 MHz.
The number of clock cycles needed per scheduling decision is: (i) a fixed cost of 20 clock cycles, plus (ii) 3 clock cycles per class, plus (iii) 4 clock cycles per weight update. In our case of 8 classes of flows, this translates into 44 clocks plus 4 cycles per weight update. Each cell arrival may result in a weight update, if it belongs to a previously idle flow (that flow must be added to the other flows of its class that are entitled for service, thus increasing the weight of that class). Similarly, each cell departure may result in a weight update, if this was the last cell of a flow and hence that flow now becomes idle. Thus, for example, a scheduler for an outgoing link that receives incoming traffic from 4 links would have to process, in the worst case, 5 weight updates per cell-time, in addition to the scheduling decision for the departing cell. These would require a total of 44 + 5*4 = 64 clock cycles, or 1.3 microsecond with a 50 MHz clock, corresponding to a rate of 330 Mbits/s per link (for ATM traffic), or 1.6 Gbits/s aggregate I/O rate.
M. Katevenis, D. Serpanos, E. Markatos: ``Multi-Queue Management and Scheduling for Improved QoS in Communication Networks'', Proceedings of EMMSEC'97 (European Multimedia Microprocessor Systems and Electronic Commerce Conference), Florence, Italy, Nov. 1997, pp. 906-913.