To avoid the additional block transfers induced by the basic parity-based redundancy schemes used in RAIDS [7], we have considered the parity logging scheme, discussed in [18], as a suitable reliability policy for the NRD. The key idea of this technique is that a given block need not be bound to a particular server or parity group. Instead, every time a block is written out, a new server and a new parity group may be used to host the block.
Using the parity logging policy with S servers, the runtime overhead of the reliability policy can be reduced to a factor of (1+1/S) of the runtime overhead without reliability. However, the parity logging policy cannot be efficiently used on our device without a major latency cost. This happens because the parity stripping unit of the parity logging policy must be fixed, and in disk devices the smallest data unit is one disk block (512 or 1024 bytes on most systems). Given that the filesystem sends a variable amount of blocks on each request (usually 1 to 8 blocks), the parity logging policy would make one small network transfer for each block, and as a result the latency of each I/O request would be a multiple of the latency of the network. For example, if we have an I/O request of 16 disk blocks the latency would be 16 times the latency of the network, which is similar, or even higher than the latency of magnetic disk.
Addressing this issue, we have developed a new reliability policy for our device to reduce both the memory overhead and the latency bottleneck for each I/O request. Our policy, which is called parity caching, uses a small amount of the NRD client's memory as a parity cache. The parity cache collects a fixed amount of disk blocks, enabling the parity caching policy to use more than one blocks as a parity stripping unit during normal operation, while it still supports recovery for each block unit in case of server failure. Obviously parity caching has much lower latency than the parity logging policy.
Before looking deeper at how parity caching functions, we need to define the concept of the parity group. A parity group as a number of data blocks and the corresponding parity block, which is formed by XORing all the data blocks. If one of the data blocks is lost, we can reconstruct the lost block by XORing all the remaining data blocks and the parity block. A parity group is depicted on figure 2 .
Suppose there exist one (reliable) client and S (unreliable) server machines, and each server can store B disk blocks. We need one server to keep the parity blocks (the parity server), while the other S-1 servers (called storage servers) store normal data blocks. Accordingly, our cache has S-1 buffers for the storage servers (storage buffers) and one for the parity server (the parity buffer). Thus the cache is a total of (X*S) blocks (1 block = 512 bytes). Each buffer in the cache corresponds to exactly one server, meaning that the blocks placed in a particular buffer will be sent and stored on its corresponding server. Such a block cache and the matching of of buffers and servers are illustrated in figure 1 for S=4 (3 storage servers and 1 parity server).
When a write request of X blocks arrives from the filesystem the client places the X blocks into one storage buffer, updating a map that shows where each block is stored. When all S-1 storage buffers in the cache are full, the client computes the X parity blocks into the parity buffer, sends away all the buffers, each to its corresponding server, and then empties the cache.
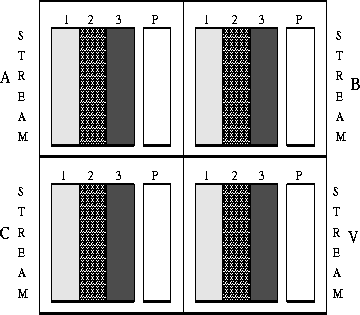
Figure 3: The Adaptive Parity Cache.