Another problem we address is the issue of redundancy cleaning. Due to the fact that a block does not have a fixed position, but can be written anywhere on any server, each time a block is overwritten the old block must be invalidated. The invalid block cannot be cleared until all the data blocks in its parity group are invalid, because it is needed in case one of the blocks in its parity group is lost. Similar behavior is encountered also in the Log-structured FileSystem (LFS) [22, 25, 20], and raises questions about the use of redundancy cleaning.
Based upon our knowledge of disk devices and filesystems we believe that blocks whose block numbers are contiguous, belong either to the same file or to file(s) that are part of a data stream, and are likely to be written, read or rewritten together. If the rewritten blocks were placed in the same parity group, that would make the redundancy cleaning of our device automatic. Using this observation we extended our parity caching policy to an adaptive parity caching policy .
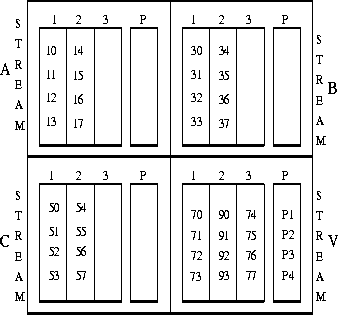
Figure 4: Parity Cache example (Phase 1) : Stream cache A accumulates
blocks 10-17, stream cache B blocks 30-37, stream cache C blocks 50-57,
and stream cache V (the victim stream cache) blocks 70-73,90-93 and 74-77.
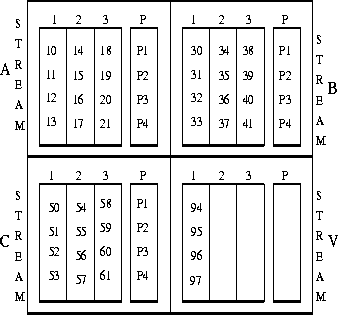
Figure 5: Parity Cache example (Phase 2) : Stream cache A accumulates
blocks 10-21, stream cache B blocks 30-41, stream cache C blocks 50-61,
and stream cache V (the victim stream cache) blocks 94-97. Each of the
first three caches have captured a single block stream.
In the adaptive caching policy we use P parity caches as the one mentioned above. We call each cache, a stream cache, because it tries to capture a single data stream. Figure 3 shows an adaptive parity cache with 3 stream caches (A, B, C) and 1 victim stream cache ( V ).
So when the client has to choose a stream cache for placing the X blocks, it performs the following placement:
An example of the above policy is illustrated in figures 4 and 5 . In this example we assume that there are S=4 servers, and each buffer is X=4 blocks in size. The filesystem makes the following write requests (in block numbers) : (10,11,12,13), (30,31,32,33), (50,51,52,53), (70,71,72,73), (90,91,92,93), (34,35,36,37), (14,15,16,17), (54,25,26,27), and (74,75,76,77). Then our cache would have the blocks placed as shown in figure 4 . The next write requests are : (18,19,20,21), (94,95,96,97), (38,39,40,41), (58,59,60,61), and our cache would be in the state of figure 5 .
It is clear that this placement policy creates many parity groups of contiguous blocks. Even when the filesystem writes in many different block streams, each stream is placed in the same stream cache. Moreover, this policy degrades gracefully when more than 4 different streams are written together. In the above example we used 5 streams and the cache managed to capture 3 of them, and mixed the last two in the best possible manner.