


Applications like multimedia, windowing systems, scientific computations, engineering simulations, etc. running on workstation clusters (or networks of PCs) require an everincreasing amount of memory, usually, more than any single workstation has available. To make matters worse, the use of multiprogramming and time-sharing further reduces the amount of physical main memory which is available to each application. To alleviate the memory shortage problem, an application could use the virtual memory paging provided by the operating system, and have some of its data in main memory and the rest on the disk. Unfortunately, as the disparity between processor and disk speeds becomes everincreasing, the cost of paging to a magnetic disk becomes unacceptable. Our performance measurements explained in section 5 suggest that the completion time of an application rises sharply when its working set exceeds the physical memory of the workstation. Faster swap disks would only temporarily remedy the situation, because processor speeds are improving at a much higher rate than disk speeds [7]. Clearly, if paging is going to have reasonable overhead, a new paging device is needed. This device should provide high bandwidth and low latency. Fortunately, a device with these characteristics exists in most distributed systems and it is not used most of the time. It is the collective memory of all the workstations, hereafter called remote memory.
Remote memory provides high transfer rates which are mainly dictated by the
interconnection network. For example,
ATM networks provide a data transfer rate of 155 Mbits/sec per link;
a transfer rate higher than any single disk can provide.
A collection of ATM links serving several sources and several destinations
may easily exceed an aggregate transfer rate
of 1 Gbit/sec, more than expensive disk arrays provide!
Fortunately, most of the time remote main memory
is unused. To verify this claim, we
profiled the unused memory of the workstations
in our lab for the duration of one week:
16 workstations with a total of 800 Mbytes
of main memory.
Figure 1 plots the free memory as a function of the day of the
week.
We see that for significant periods of time
more than 700 Mbytes are unused, especially during the nights,
and the weekend. Although during business hours the
amount of free memory falls, it is rarely lower than 400 Mbytes!
Thus, even at business hours there is a significant amount of
main memory that could be used by applications that need more memory
than a single workstation provides.
for the duration of one week:
16 workstations with a total of 800 Mbytes
of main memory.
Figure 1 plots the free memory as a function of the day of the
week.
We see that for significant periods of time
more than 700 Mbytes are unused, especially during the nights,
and the weekend. Although during business hours the
amount of free memory falls, it is rarely lower than 400 Mbytes!
Thus, even at business hours there is a significant amount of
main memory that could be used by applications that need more memory
than a single workstation provides.
Architecture and software developments suggest that the use of remote memory for paging purposes is possible and efficient:
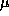 s.
The ability to perform single remote memory accesses efficiently,
will enhance the performance of a remote memory paging policy significantly.
If, for example, an application needs to make just a few accesses
to a page, then
it is not worthwhile to bring the entire page from
remote memory, replacing an already resident
and potentially more useful page. If the
network provides the ability of efficient
single remote accesses, the application can use
these to access infrequently used pages.
s.
The ability to perform single remote memory accesses efficiently,
will enhance the performance of a remote memory paging policy significantly.
If, for example, an application needs to make just a few accesses
to a page, then
it is not worthwhile to bring the entire page from
remote memory, replacing an already resident
and potentially more useful page. If the
network provides the ability of efficient
single remote accesses, the application can use
these to access infrequently used pages.
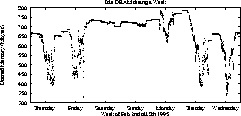
Figure 1: Unused memory in a workstation cluster.
The figure plots
the idle memory during a typical week
in the workstations of our lab: a total of 16 workstations
with about 800 Mbytes of total memory.
We see that memory usage was at each peak (and thus free memory was scarce)
at noon and afternoon. Only exception were days 2-4 that were
the weekend. In all times though, more than 300 Mbytes of main memory
were unused.
In this paper we show that it is both possible and beneficial
to use remote memory
as a a paging device, by building the
systems software that transparently transfers operating system
pages across workstation memories within a workstation
cluster.
We describe a pager built as a device driver of the
DEC/OSF1 operating system. Our pager is completely portable to
any system that runs DEC/OSF, because we didn't modify the operating system
kernel .
More important, by running real applications on top of our
memory manager, we show that even on top of slow interconnection
networks (like Ethernet), it is efficient to use remote memory
as backing store.
Our performance results suggest that
paging to remote memory over Ethernet,
rather than paging to a
local disk of comparable bandwidth,
results in up to 112% faster
execution times for real applications.
Moreover, we show that reliability and redundancy
comes at no significant extra cost. We describe the implementation
and evaluation of several reliability policies that keep some
form of redundant information, which enables the application
to recover its data in case a workstation in the distributed
system crashes.
Finally, we use extrapolation to find the performance
of paging to remote memory over faster networks like FDDI and ATM.
Our extrapolated results suggest that paging over a 100 Mbits/sec
interconnection network, reduces paging overhead to only 20% of the
total execution time.
Faster networks will reduce this overhead even more.
The rest of the paper is organized as follows: Section 2 presents related work. Section 3 presents the design of a remote memory pager and the issues involved. Section 4 presents the implementation of the pager as a device driver. Section 5 presents our performance results which are very encouraging. Section 6 presents some aspects that we plan to explore as part of our future work. Finally, section 7 presents our conclusions.